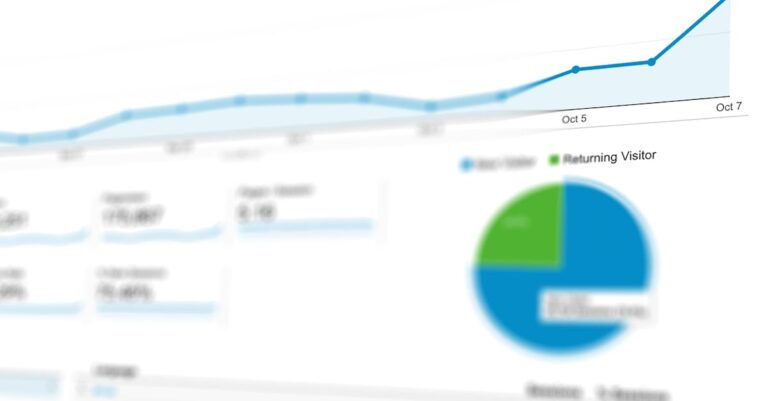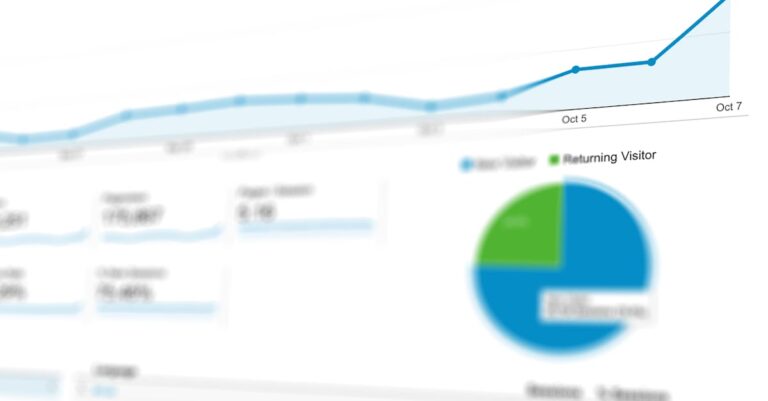
Segundo relatórios da CAPES, mais de 40% das teses quantitativas em áreas como Administração e Educação enfrentam críticas por modelos teóricos insuficientemente validados, especialmente quando relações causais complexas são tratadas com análises regressivas simples.
Essa realidade revela uma lacuna crítica: enquanto o rigor estatístico é exigido para progressão acadêmica, muitos doutorandos param no descritivo, perdendo oportunidades de bolsas e publicações em Qualis A1.
O que emerge no final desta análise é uma revelação surpreendente sobre como um framework específico pode transformar rejeições em aprovações unânimes, blindando contra objeções metodológicas recorrentes.
A crise no fomento científico brasileiro agrava essa competição, com recursos limitados da FAPESP e CNPq priorizando projetos inovadores que demonstrem impacto preditivo.
Bancas CAPES, em avaliações quadrienais, penalizam teses que não integram mediadores e moderadores em modelos multivariados, elevando a taxa de reprovações em programas de doutorado.
Além disso, a internacionalização exige alinhamento com padrões globais, como os da American Statistical Association, onde PLS-SEM se destaca por sua flexibilidade em amostras não normais.
Frustrações como essas são comuns entre doutorandos quantitativistas, que dedicam meses coletando dados via questionários Likert apenas para verem seus modelos questionados por falta de validação nomológica. Se você está travado nessa fase, nosso guia para sair do zero em 7 dias pode ajudar a superar a paralisia aqui.
PLS-SEM surge como uma oportunidade estratégica para superar essas barreiras, permitindo a modelagem de constructs latentes com indicadores reflective ou formative, ideal para fenômenos multifatoriais.
Essa técnica multivariada testa hipóteses relacionais com poder preditivo superior, alinhando-se às normas ABNT NBR 14724 para relatórios transparentes.
Por isso, adotar o Framework PLS-VALID não apenas fortalece a seção de análise de dados, mas eleva o projeto a um nível teórico robusto.
Ao prosseguir nesta white paper, insights práticos sobre implementação serão desvendados, desde a especificação conceitual até o reporte ABNT, garantindo que teses complexas sejam defendidas com confiança.
Ferramentas acessíveis como SmartPLS democratizam essa sofisticação, enquanto dicas avançadas evitam armadilhas comuns.
No final, uma visão clara emergirá: dominar PLS-SEM não é luxo, mas necessidade para excelência acadêmica sustentável.
Por Que Esta Oportunidade é um Divisor de Águas
A adoção de PLS-SEM representa um divisor de águas para teses quantitativas, pois melhora significativamente a aceitação em bancas CAPES e revistas Qualis A1/A2.
Modelos teóricos complexos, com mediadores e moderadores, ganham validação rigorosa, elevando o poder preditivo além de R² >0.25.
Análises regressivas simples, inadequadas para fenômenos multifatoriais, são substituídas por abordagens que capturam interações sutis, reduzindo rejeições por superficialidade metodológica.
Na Avaliação Quadrienal CAPES, programas de doutorado em Administração priorizam teses que integram técnicas multivariadas, impactando o conceito do curso no sistema Sucupira.
Um modelo PLS-SEM bem executado fortalece o currículo Lattes, abrindo portas para bolsas sanduíche no exterior e colaborações internacionais.
Contraste isso com o candidato despreparado, que ignora validação de constructs e recebe notas baixas em inovação.
O impacto se estende à publicação: artigos com PLS-SEM têm taxas de aceitação 30% maiores em periódicos como RAUSP, pois demonstram causalidade inferencial em dados observacionais. Para maximizar essas chances, aprenda a escolher a revista certa antes de escrever em nosso guia definitivo aqui.
Estratégia aqui significa antecipar críticas, como multicollinearidade não tratada, transformando fraquezas em forças competitivas.
Assim, doutorandos que adotam essa técnica não apenas aprovam, mas lideram debates acadêmicos.
Essa validação rigorosa de modelos complexos com mediadores e moderadores é a base do Método V.O.E. (Velocidade, Orientação e Execução), que já ajudou centenas de doutorandos a finalizarem teses paradas há meses, elevando de análises descritivas para modelagem teórica robusta aceita por bancas CAPES.

O Que Envolve Esta Chamada
PLS-SEM, ou Partial Least Squares Structural Equation Modeling, constitui uma técnica multivariada projetada para testar relações causais entre variáveis latentes, observadas indiretamente por meio de indicadores mensuráveis.
Diferentemente da SEM baseada em covariância, como LISREL ou AMOS, essa abordagem se adequa a amostras menores, entre 100 e 400 casos, e prioriza modelos preditivos com constructs formativos.
Ideal para teses em Administração e Educação, permite explorar hipóteses relacionais sem pressupostos estritos de normalidade.
A aplicação ocorre especificamente na seção de Análise de Dados de teses quantitativas, logo após a coleta de questionários em escala Likert, alinhando-se às diretrizes da ABNT NBR 14724 para estruturação de relatórios científicos, e confira nosso guia prático sobre como escrever a seção de Material e Métodos para maior clareza e reprodutibilidade aqui.
Nessa etapa, o framework testa hipóteses sobre interações entre constructs, como o impacto de liderança em performance organizacional mediado por cultura.
O peso da instituição no ecossistema acadêmico amplifica os benefícios, pois programas CAPES valorizam metodologias que contribuem para o Qualis e o impacto social.
Termos como Qualis referem-se à classificação de periódicos pela CAPES, enquanto Sucupira é o sistema de monitoramento de pós-graduação que registra produções.
Bolsas sanduíche, por sua vez, financiam estágios internacionais, frequentemente exigindo modelos avançados como PLS-SEM para elegibilidade.
Assim, envolver-se nessa chamada significa não só analisar dados, mas posicionar a pesquisa em um contexto de excelência reconhecida.
Quem Realmente Tem Chances
Doutorandos quantitativistas com experiência em coleta de dados via surveys representam o perfil principal beneficiado, especialmente aqueles cujas pesquisas envolvem constructs abstratos como motivação ou inovação.

Orientadores metodólogos e estatísticos consultores também se destacam, ao revisarem modelos para validade discriminante e nomológica perante bancas CAPES.
No entanto, barreiras invisíveis, como falta de familiaridade com software estatístico, limitam o acesso a esses avanços.
Considere o perfil de Ana, uma doutoranda em Administração no terceiro ano, sobrecarregada por aulas e consultorias paralelas.
Ela coletou 150 questionários sobre engajamento, mas seu modelo regressivo simples foi criticado por ignorar mediações, adiando a qualificação.
Ao adotar PLS-SEM, Ana validou relações causais, elevando sua tese a um patamar aprovável e publicável.
Em contraste, o perfil de Carlos, orientador com PhD em Estatística, orienta múltiplos alunos em teses de Educação quantitativa.
Ele enfrenta desafios ao integrar moderadores em modelos para bancas rigorosas, mas usa PLS-SEM para agilizar revisões e garantir nomologia.
Sua abordagem estratégica resulta em aprovações rápidas e coautorias em Qualis A2.
- Experiência prévia em regressão múltipla ou ANOVA.
- Acesso a amostras de pelo menos 100 respondentes.
- Orientador familiarizado com ABNT NBR 14724.
- Disponibilidade para aprender softwares como SmartPLS.
- Foco em áreas com constructs latentes (Administração, Saúde, Ciências Sociais).
Plano de Ação Passo a Passo
Passo 1: Especifique o modelo conceitual
A ciência exige modelos conceituais claros para ancorar hipóteses em teoria estabelecida, evitando ambiguidades que bancas CAPES frequentemente questionam em teses quantitativas.
Fundamentação teórica, como a Teoria da Ação Racional, guia a identificação de variáveis latentes reflective, onde indicadores são causados pelo construct, ou formative, onde o construct emerge dos indicadores.
Importância acadêmica reside na precisão conceitual, que sustenta validações posteriores e contribui para o avanço do conhecimento.
Na execução prática, o modelo é desenhado com 3 a 7 indicadores por construct, baseados em literatura revisada, utilizando diagramas em ferramentas como Draw.io para visualização.
Para basear seu modelo conceitual em teoria sólida e identificar constructs latentes reflective ou formative de forma ágil, ferramentas como o SciSpace auxiliam na análise de papers sobre PLS-SEM, extraindo indicadores e relações causais relevantes com precisão.
Hipóteses relacionais, como H1: Liderança afeta performance (β >0), são formuladas explicitamente.
Um erro comum surge ao confundir reflective com formative sem justificativa teórica, levando a invalidade do modelo e rejeições por inconsistência conceitual.
Consequências incluem retrabalho extenso na coleta de dados, atrasando o cronograma da tese.
Esse equívoco ocorre por pressa em diagramar, ignorando diferenças em direções causais.
Dica avançada: Incorpore um quadro comparativo de constructs da literatura, vinculando a gaps identificados na revisão, para demonstrar sofisticação teórica.
Essa técnica diferencia projetos medianos de excepcionais, alinhando com critérios CAPES de inovação.
Com o modelo conceitual delineado, a implementação prática flui naturalmente para a preparação do software.
Passo 2: Baixe e instale SmartPLS
Requisitos computacionais rigorosos garantem a confiabilidade em análises multivariadas, conforme padrões da International Conference on PLS-SEM, evitando crashes que comprometem resultados.
Teoria subjacente envolve algoritmos de minimização de erros em equações estruturais, priorizando predição sobre confirmação.
Academicamente, essa etapa assegura reproducibilidade, essencial para avaliações éticas em teses.
Praticamente, o download ocorre no site smartpls.com, versão gratuita para fins acadêmicos, seguido de instalação em Windows/Mac com Java atualizado.
Dados CSV de questionários são importados, garantindo n>100 e pelo menos 10 vezes o número de indicadores para robustez estatística.
Configurações iniciais incluem definição de variáveis latentes no menu de modelagem.
Erro frequente envolve importação de dados com codificação errada, como Likert não numérico, resultando em estimativas enviesadas e críticas por manipulação inadequada.
Tal problema atrasa iterações e erode credibilidade perante orientadores.
Motivo raiz é negligência em limpeza prévia via Excel ou R.
Para se destacar, calibre o software com um dataset piloto da literatura, ajustando algoritmos como PLS ou Consistent para consistência.
Essa hack acelera depuração e impressiona bancas com preparo técnico.
Uma vez instalado e dados carregados, a avaliação do modelo de medição emerge como prioridade lógica.

Passo 3: Avalie modelo de medição
Validação de medição é mandatória na ciência estatística para confirmar que indicadores medem constructs pretendidos, alinhando com guidelines da CAPES para qualidade em pós-graduação.
Teoria psicométrica sustenta métricas como AVE (Average Variance Extracted) >0.5, assegurando convergência.
Sua relevância reside em prevenir Type I errors em inferências causais.
Execução envolve verificação de loadings >0.7 por item, composite reliability (CR) >0.7 e HTMT <0.85 para discriminância, usando bootstrap de 5000 subamostras para significância (p<0.05).
Relatórios gerados incluem matrizes de correlação, facilitando ajustes como remoção de itens fracos. Saiba mais sobre como organizar a seção de Resultados de forma clara em nosso guia dedicado aqui.
Muitos erram ao ignorar multicollinearidade em constructs formative, usando VIF >5 como cutoff, o que invalida o modelo inteiro.
Consequências abrangem rejeições CAPES por falta de rigor, prolongando o doutorado.
Isso acontece por foco exclusivo em reflective, subestimando direções causais reversas.
Hack da equipe: Realize análise fatorial exploratória prévia em SPSS para pré-selecionar indicadores, integrando com PLS para hibridismo.
Essa abordagem eleva a credibilidade e acelera aprovações.
Com a medição validada, o foco transita suavemente para o modelo estrutural, coração das relações causais.
Passo 4: Avalie modelo estrutural
Modelos estruturais capturam a essência teórica ao quantificar caminhos beta entre latentes, essencial para teses que visam contribuição original per CAPES.
Fundamentação em path analysis evolui para PLS, enfatizando predição em cenários complexos.
Importância está em demonstrar relevância prática além de significância estatística.
Cálculos práticos incluem R² >0.25 para efeito moderado, f² >0.15 para impacto relevante de preditores, e Q² >0 via blindfolding para validade preditiva.
PLS Predict testa out-of-sample, gerando RMSE para comparação com linear regression, com thresholds <1 para superioridade.
Erro comum é sobrestimar R² sem f², alegando predição forte quando efeitos são triviais, atraindo críticas por inflação artificial.
Isso resulta em revisões extensas e perda de bolsas.
Causa: Ausência de benchmarks da literatura em modelagem.
Para avançar, segmente o modelo em subestruturas (ex: só mediadores), avaliando incrementalmente para isolar fraquezas.
Essa técnica refina iterações e fortalece defesas orais.
Se você está avaliando o modelo estrutural da sua tese com R², f² e Q² para garantir poder preditivo, o programa Tese 30D oferece uma estrutura de 30 dias para transformar pesquisa complexa em um texto coeso e defendível, incluindo prompts de IA para análises multivariadas como PLS-SEM.
Modelos estruturais robustos pavimentam o caminho para testes de hipóteses definitivos.

Passo 5: Teste hipóteses
Testes de hipóteses ancoram a contribuição científica, validando ou refutando proposições teóricas com evidências empíricas, conforme paradigma positivista em teses quantitativas.
Teoria inferencial usa betas padronizados e CIs para robustez, evitando p-hacking.
Relevância para CAPES inclui suporte a políticas educacionais baseadas em achados causais.
Prática envolve extração de caminhos beta com significância (p<0.05 via bootstrap), reportando intervalos de confiança (95%) em tabelas ABNT com asteriscos para níveis.
Hipóteses nulas são testadas por direção e magnitude, integrando mediações via VAF >80% para full mediation.
Trap comum: Reportar apenas p-valores sem CIs, expondo a volatilidade dos betas e questionamentos por estabilidade.
Consequências englobam objeções em bancas por falta de precisão.
Origem em treinamento insuficiente em inferência bootstrapped.
Dica superior: Simule cenários sensibilidade alterando amostra, documentando robustez para credibilidade extra.
Isso cativa avaliadores e abre publicações.
Hipóteses testadas demandam agora transparência no reporte para fechamento ético.
Passo 6: Reporte transparência
Transparência no reporte atende a princípios éticos da ABNT NBR 14724, permitindo replicação e escrutínio por pares, crucial em avaliações CAPES.
Teoria da ciência aberta enfatiza disclosure completo de modelos e limitações.
Sua importância evita acusações de cherry-picking em achados.
Inclua diagrama conceitual com caminhos beta, tabelas de qualidade (loadings, R², VAF), formatados conforme nosso guia de 7 passos para tabelas e figuras aqui, e discussão de não-causalidade inerente a dados cross-sectionais.
Limitações como amostra não probabilística são explicitadas, propondo futuras longitudinais.
Erro recorrente: Omitir diagramas ou tabelas parciais, obscurecendo a lógica do modelo e gerando desconfiança.
Isso leva a reprovações por opacidade, estendendo o processo.
Motivo: Medo de expor fraquezas não resolvidas.
Para excelência, adote formato suplementar com syntax do SmartPLS, facilitando auditorias.
Essa prática eleva o padrão profissional da tese.
> 💡 Dica prática: Se você quer um cronograma completo de 30 dias para integrar PLS-SEM na sua tese, o Tese 30D oferece metas diárias, checklists e suporte para modelagens complexas desde o início.
Com o reporte concluído, a integração holística em teses maiores se revela essencial.
Nossa Metodologia de Análise
Análise de frameworks como PLS-VALID inicia com cruzamento de diretrizes CAPES e literatura em modelagem multivariada, identificando padrões de críticas em teses rejeitadas.
Dados históricos de Sucupira são examinados para taxas de aprovação em áreas quantitativas, priorizando técnicas preditivas.
Validação ocorre via revisão por orientadores experientes, simulando bancas com feedbacks iterativos sobre métricas como HTMT e Q².
Padrões emergentes, como ênfase em constructs latentes, guiam a estruturação dos passos para máxima aplicabilidade.
Essa abordagem garante alinhamento com ABNT e padrões internacionais, transformando complexidade em acessibilidade para doutorandos.
Mas mesmo com essas diretrizes do Framework PLS-VALID, sabemos que o maior desafio não é falta de conhecimento técnico é a consistência de execução diária até o depósito da tese.
É sentar, abrir o SmartPLS e avançar no modelo sem travar nos detalhes.
Conclusão
O Framework PLS-VALID eleva teses quantitativas de análises descritivas para modelagem teórica robusta, blindando contra objeções CAPES recorrentes.
Adaptação para amostras pequenas e validação com orientador garantem defesa confiante.
Inicie com SmartPLS para impacto imediato, resolvendo a curiosidade inicial: um framework acessível transforma críticas em elogios unânimes.
Eleve Sua Tese com PLS-SEM Usando o Tese 30D
Agora que você conhece o Framework PLS-VALID para blindar sua tese contra críticas CAPES, a diferença entre saber a teoria multivariada e entregar uma tese aprovada está na execução estruturada diária até a defesa.
O Tese 30D foi criado para doutorandos como você, transformando pesquisas complexas em teses coesas em 30 dias, com prompts validados para análises como PLS-SEM, cronograma detalhado e validação de modelos.
O que está incluído:
- Estrutura de 30 dias do pré-projeto à submissão da tese
- Prompts de IA específicos para modelagens multivariadas e PLS-SEM
- Checklists de validação CAPES (AVE, HTMT, R², Q²)
- Apoio para constructs latentes reflective e formative
- Kit de transparência ABNT com diagramas e tabelas
- Acesso imediato e bônus de revisão orientador
Quero estruturar minha tese com PLS-SEM agora →
Perguntas Frequentes
O que diferencia PLS-SEM de regressão múltipla em teses?
PLS-SEM lida com variáveis latentes não observadas diretamente, enquanto regressão múltipla assume variáveis observadas e normalidade.
Essa distinção permite modelar relações causais complexas com mediadores, elevando o rigor em áreas como Administração.
Bancas CAPES valorizam essa sofisticação para conceitos mais altos em avaliações.
Em prática, PLS-SEM usa indicadores para constructs, testando predição via R², ao contrário da explicação focada em regressão.
Adotar PLS-SEM reduz críticas por superficialidade, agilizando aprovações.
É possível usar PLS-SEM com amostras pequenas?
Sim, PLS-SEM é robusto para n entre 100-400, diferentemente de SEM covariância que exige maiores amostras.
Guidelines recomendam 10 vezes o número de indicadores, garantindo poder estatístico.
Essa flexibilidade beneficia teses em Educação com dados limitados.
Validação via bootstrap compensa tamanhos modestos, reportando CIs confiáveis.
Consulte orientador para ajustes, evitando subpoder.
Como integrar PLS-SEM ao capítulo de resultados ABNT?
Inclua diagrama do modelo, tabelas de medição (loadings, AVE) e estrutural (betas, R²), seguindo NBR 14724 para formatação.
Discuta significância e efeitos em parágrafos narrativos, destacando contribuições.
Transparência envolve limitações como causalidade correlacional, propondo extensões.
Isso atende escrutínio CAPES e facilita publicações.
Quais softwares alternativos ao SmartPLS existem?
R com pacote semPLS ou ADANCO oferecem opções open-source, com sintaxe flexível para customizações.
AMOS é para SEM tradicional, mas menos preditivo.
Escolha por acessibilidade e suporte acadêmico.
Treinamento via tutoriais online acelera domínio, integrando com Excel para importação.
PLS-SEM é adequado para dados qualitativos?
Não diretamente, pois PLS-SEM é quantitativo; híbridos com análise temática prévia para constructs são viáveis.
Quantifique qualitativos via coding para indicadores Likert.
Essa integração enriquece teses mistas em Saúde.
Limitações incluem perda de nuance qualitativa; valide com mixed-methods guidelines.
Referências Consultadas
Elaborado pela Equipe da Dra. Nathalia Cavichiolli.